
https://www.credly.com/badges/2e8a8866-90ff-4802-a8d9-28897328418f/public_url
Validity: 2025-05-20 – 2028-05-20
https://www.credly.com/badges/2e8a8866-90ff-4802-a8d9-28897328418f/public_url
Validity: 2025-05-20 – 2028-05-20
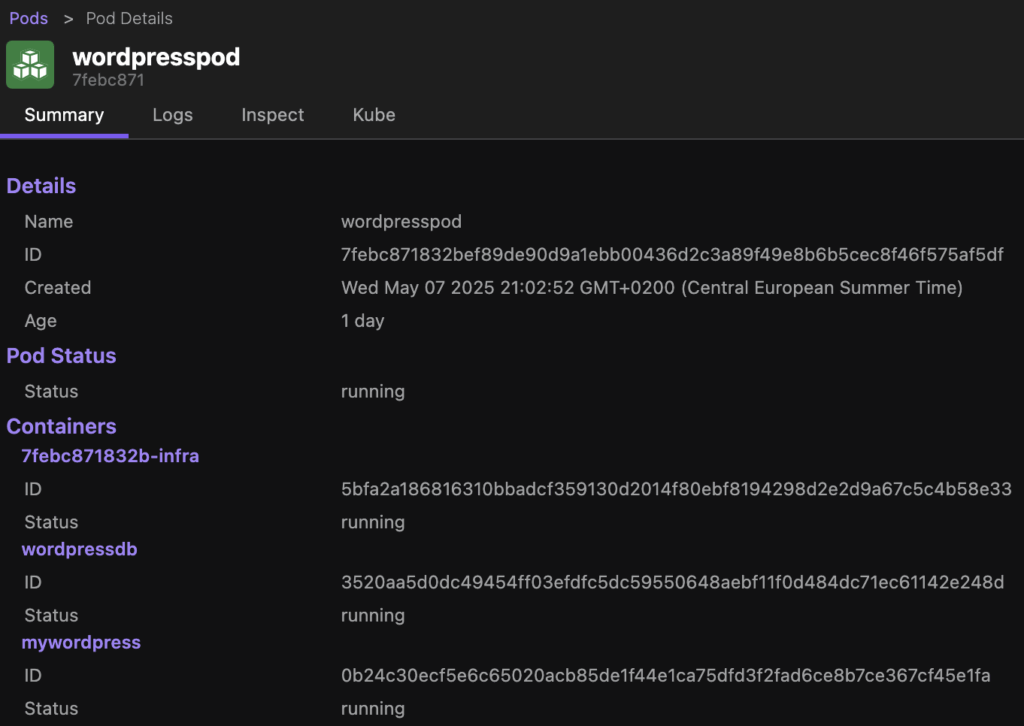
I finally migrated my wordpress blog over from https://teddy.spacetechnology.net to https://myblog.kobaan.nl
The whole thing now runs in a podman pod on the “smaller” 256GB MacStudio, as compared to the tight FreeBSD jail before.
All my docker images are automatically updated using watchtower, and wordpress also uses auto update.
Unfortunately the migration broke 5 times, as I had to readjust resources a lot. And finally changing the domain broke 1400 links, which I had to repair. Now still some images are mysteriously unlinked although the media browser can see them. I try to fix that the next days…
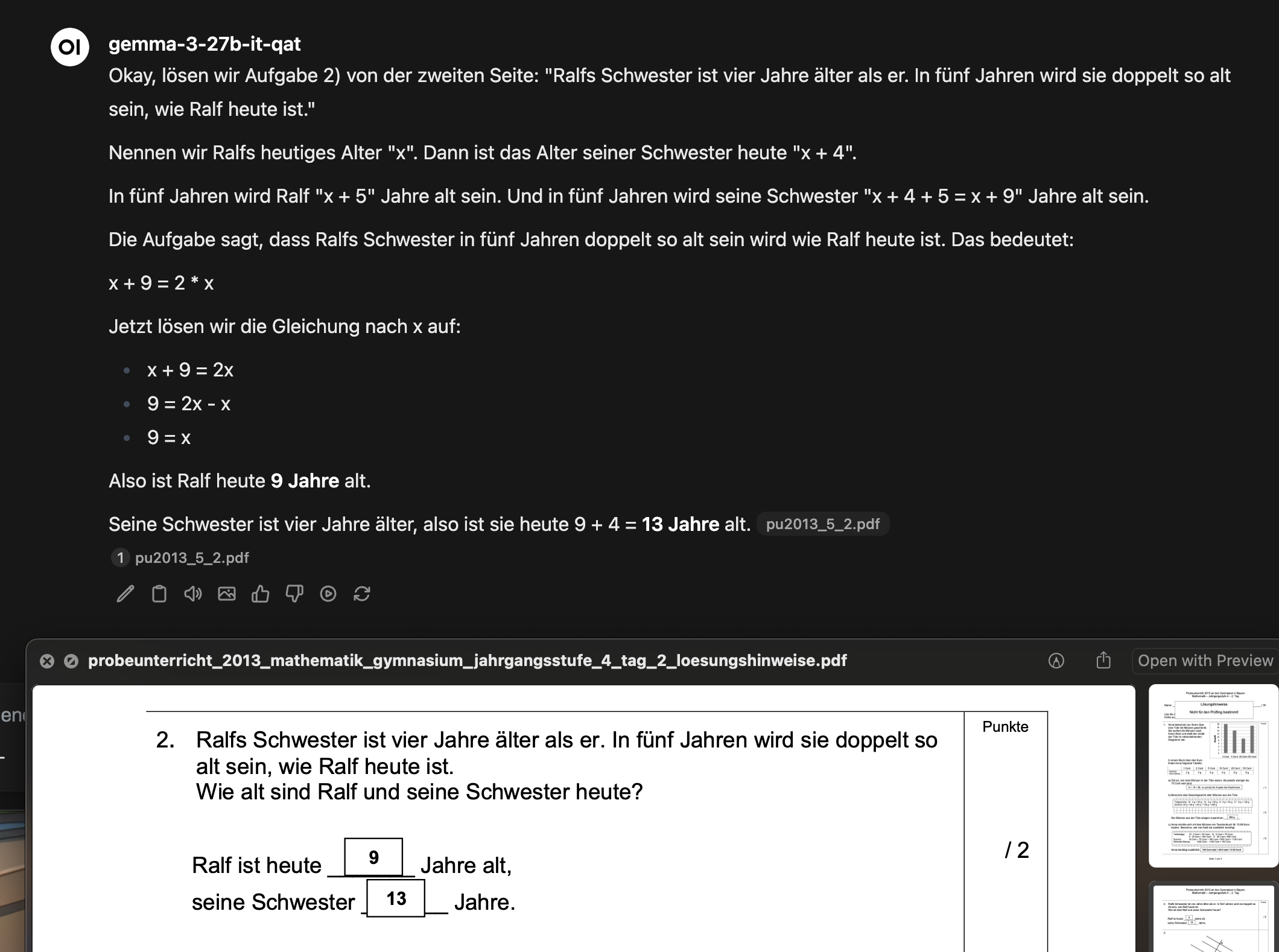
Finally got the PDF OCR flow working, and the LLM can now solve math problems. Only grey diagrams are still hard for it to recognize properly.
I used a math training exam that my son is currently working on in preparation for Gymnasium.
And even the 27B model is sufficient to solve this level of math.
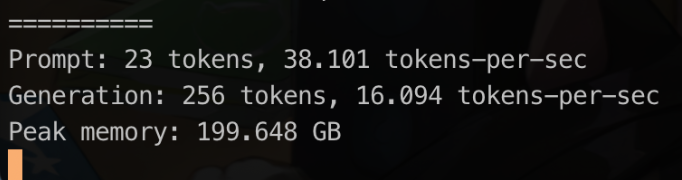
Did I say enough…..
meh….
Okay lesson learned, never enough.
My “1 month old” M3 Ultra 256GB went out of memory running all those models and podman containers in parallel.
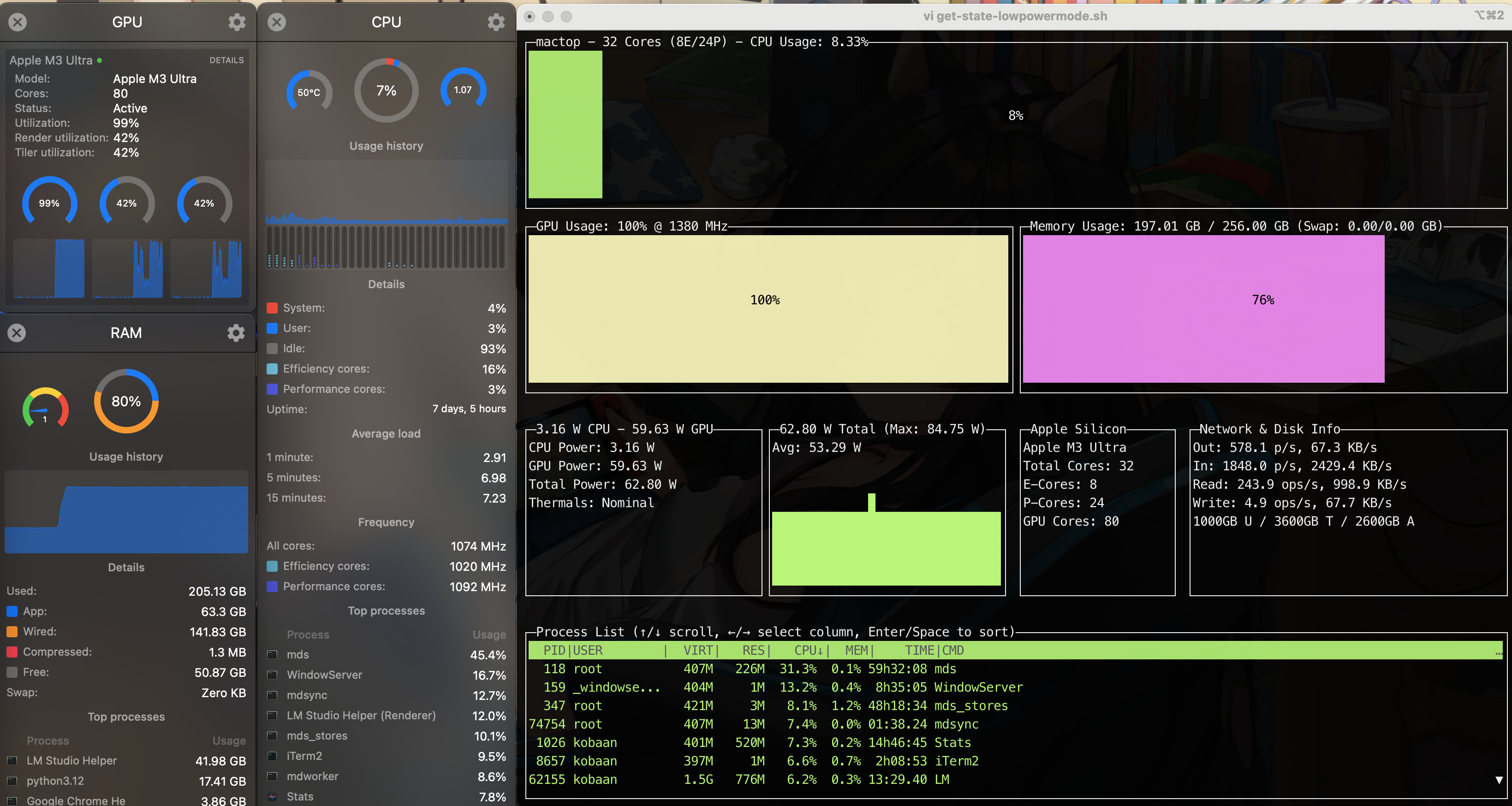
My current setup is:
OpenWebUI:
-> LM Studio, Aya-Vision-32b,
-> ComfyUI workflow with t5xxl, Flux1.dev, llama-3.1
-> MCP proxified: Searxng, wikipedia, docling, context7, time, memory, weather, sequential-thinking
Podman: 24 containers including supabase, wikijs, watchtower…
Also I discovered that I can use OpenWebUI, SwarmUI, exo and even mlx
to distribute workload across both Mac Studios via 80GBs thunderbolt 5 bridging.
And with the orange clown, you never know if there will be a new M4 Ultra next year at all.

This evening: lamb’s lettuce salad with beetroot, walnuts, feta and flowers.

What a crazy efficiency monster.
Running a LLM on all 80 GPU cores and the system is only drawing 84 Watts…..
Nvidia must be crying at night.
and this is only M3, M4 is even more efficient, but yet not available as an ultra fusion variant, and end of year Apple will manufacture in 2nm
about tonight’s plan…

yep, seems to work…
with vegetables

Finally the latest Mac Studio was released, unfortunately only with M3 chip instead of a M4, but I simply waited too long already.
Let’s see how this one compares to the previous M4 Pro I bought for my son in regards to LLM’s.
This one will be used with Podman Desktop, LM Studio and hopefully be fast enough to also handle voice recognition and rendering in realtime.
256GB VRAM will be more than enough for my use cases, 96GB was simply not enough as I already saw that on the 64GB M4.

after waiting for some months…. around xmas 2024
and it was close to be cancelled, as it was too big for the elevator,
those poor guys needed to carry it up the stairs
